开始涉猎基于知识的文本生成任务(Text Generation),重点主要在外部知识的嵌入(embedding)和编码(encoding)以及如何将编码后的知识集成到文本生成任务当中。其中的知识一般是三元组形式(triplet)也可以是非结构化的自然语言文本;所涉及的生成任务包括对话生成、生成式问答系统、故事结尾推测及补全等。-后续可能还会更新-
Introduction
早期的基于神经网络的文本生成任务大多是纯数据驱动的基于Seq2Seq框架的(暴力)模型,甚至是直接将NMT任务的Encoder-Decoder框架搬过来,仅仅是换了个数据集进行调参(如今这种灌水肯定是不行了)。这样直接生搬硬套的模型虽然确实产生了一些有意思的结果,生成的文本看上去很接近自然语言,但是过于ambiguous往往缺乏有实质信息(informative)的内容。我们就从直觉出发,显然一个正常人在对话和写作过程会加入个人的经验、常识等超出上下文内容的信息,因此将外界知识引入是必不可少的。无论是对自然语言的理解(NLU)还是生成自然语言(NLG),知识的引入都肯定会使系统效果有显著提升。从训练数据上来看,我们要完成从对上下文的理解、推理最后到文本的生成,上下文中出现的一些实体(entity)隐含的关系、性质等信息往往要借助外界知识才能完善,这些关系性质仅仅从训练数据集中是无法获取和推理的,直接去拟合上下文的匹配其结果往往只能使系统学习到语法结构和一些最简单最基本的标准 response。
Augmenting End-to-End Dialogue System with Commonsense Knowledge
https://arxiv.org/pdf/1709.05453.pdf
Motivation
在人类对话中,人们不仅仅只关注于对话内容本身,还要将对话中各种概念的相关信息集成在回复中。由于常识知识(commonsense knowledge)可以说是海量的,作者认为运用一个包含常识的外部记忆模块比传统方法中强迫系统去将这些海量的知识编码在模型参数中更为可靠。在论文中作者测试了用常识知识来增强End2End的对话系统。
Model
论文的数据集是形如 <$message$, $response$, $label$> 的三元组,$label$ 用来标识 $response$ 是否和 $message$ 匹配,目标模型其实是一个二分类模型,因此我们主要关注 commonsense knowledge 的 embedding 和 encoding。
论文的commonsense knowledge采用通过ConceptNet获取的三元组 <$concept1$, $relation$, $concept2$> 作为assertion并假设commonsense knowledge base由大量关于concepts $C$ 的 assertions $A$ 组成。值得注意的是,concept $c$ 可以是单个单词也可以是多个单词。作者构建了一个以 $c$ 作为key,以所有包含 $c$(可以是 $concept1$ 或 $concept2$)的assertions作为value的字典。设 $A_x$ 为message $x$ 中所有相关的assertions的集合,作者通过n-gram matching的方法将match到的concept对应的所有assertions加入到 $A_x$。

论文使用LSTM来encoding $A_x$ 中的所有assertions。每个形如 <$c_1$, $r$, $c_2$> 的 $a$ 都被视为一个tokens序列,e.g.对于multi-word concept $c_1$, $c_2$, $a$ = $[c_{11}, c_{12}, c_{13}…, r, c_{21}, c_{22}, c_{23}…]$ 。作者将concept和relation中的词当作常规词一并加入vocabulary $V$ 中进行embedding。
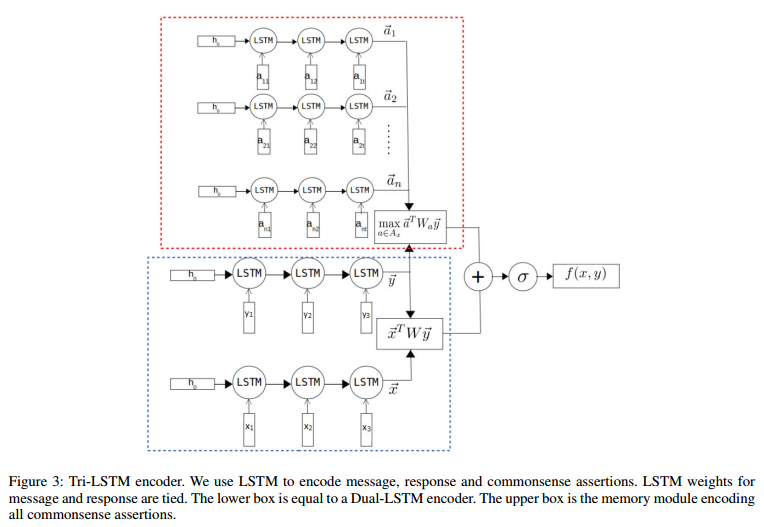
我们不详细讨论模型后面的task-orient部分。但是从上图可以看到,作者没有显式计算assertions $a$ 与message $x$ 的相关性score,而是分别计算response $y$ 与 message $x$ 和 assertions $a$ 的score。可以认为assertions $a$ 的集成,其本质就是给原模型加入了一个response要与message中出现的concept1的通过某种relation关联的concept2相关的先验偏好。(个人认为在对message进行encoding的过程中也有必要加入commonsense knowledge,因为前面的词的相关concept可能对后面的词的语义产生影响。)
之后作者还提出了一个变种:
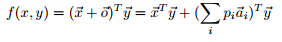
其中 $p_i$ 是 $x$ 对 $a_i$ 的dot-product attention score,使与message context相关性高的assertion具有更大的权值。作者在这里把 $A_x$ 视作Memory Networks的memory component。
Commonsense Knowledge Aware Conversation Generation with Graph Attention
https://www.ijcai.org/proceedings/2018/0643.pdf
(Paperweekly上正好有对这篇paper的解读,很多内容直接搬运了)
Motivation
在以前的工作中,对话生成的信息源是文本与对话记录。但是这样一来,如果遇到OOV的词,模型往往难以生成合适的、有信息量的回复,而会产生一些低质量的、模棱两可的回复,这种回复往往质量不高。
为了解决这个问题,有一些利用常识知识图谱生成对话的模型被陆续提出。当使用常识性知识图谱时,由于具备背景知识,模型更可能理解用户的输入,这样就能生成更加合适的回复。但是,这些结合了文本、对话记录、常识知识图谱的方法,往往只使用了单一三元组,而忽略了一个子图的整体语义,会导致得到的信息不够丰富。
为了解决这些问题,文章提出了一种基于常识知识图谱的对话模型(commonsense knowledge aware conversational model, CCM)来理解对话,并且产生信息丰富且合适的回复。
本文提出的方法利用了大规模的常识性知识图谱。 首先是理解用户请求,找到可能相关的知识图谱子图;再利用静态图注意力(static graph attention)机制,结合子图来理解用户请求;最后使用动态图注意力(dynamic graph attention)机制来读取子图,并产生合适回复。
通过这样的方法,本文提出的模型可以生成合适的、有丰富信息的对话,提高对话系统的质量。
Model
1. CCM模型
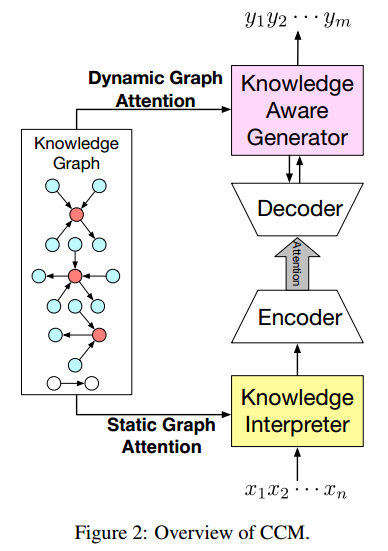
如图所示,基于n个词的输入,会输出m个词作为回复,模型的目的就是预估这么一个概率分布 $P(Y|X,G)=\Pi^m_{t=1}P(y_t|y_{<t},X,G)$,即将图信息 $G$ 加入到概率分布的计算中。
在信息读取时,根据每个输入的词 $x$,找到常识知识图谱中对应的子图(若没有对应的子图,则会生成一个特殊的图 Not_A_Fact),每个子图又包含若干三元组。
2. 知识编译模块(Knowledge Interpreter)
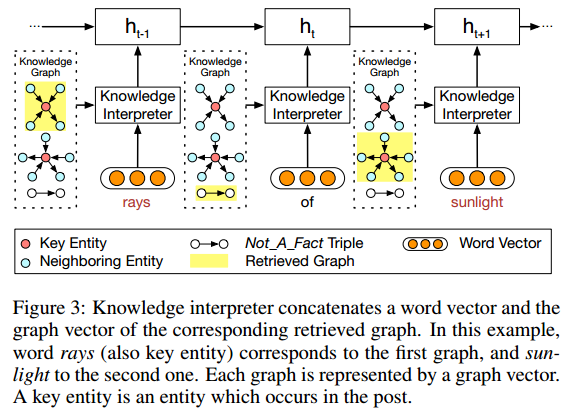
如图所示,当编译到”rays”时,会把这个词在知识图谱中相关的子图得到,并生成子图向量。每一个子图都包含了key entity(即这里的”rays”),以及这个”rays”的邻居实体和相连关系。
对于词”of”,由于无法找到对应子图,所以就采用特殊子图 Not_A_Fact 来编译。之后采用基于静态注意力机制,CCM会将子图映射为向量,然后把词向量 $w(x_t)$ 和 $g_i$ 拼接作为encoder中GRU的输入。
对于静态图注意力机制,CCM将子图中所有三元组 $k_n=(h_n, r_n, t_n)$ 考虑进来:
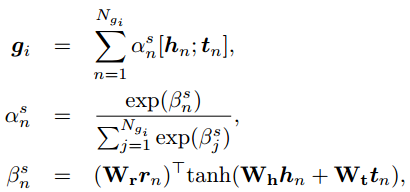
其中三元组 $k_n=(h_n, r_n, t_n)$ 选用TranE进行embedding。
3. 知识生成模块(Knowledge Aware Generator)
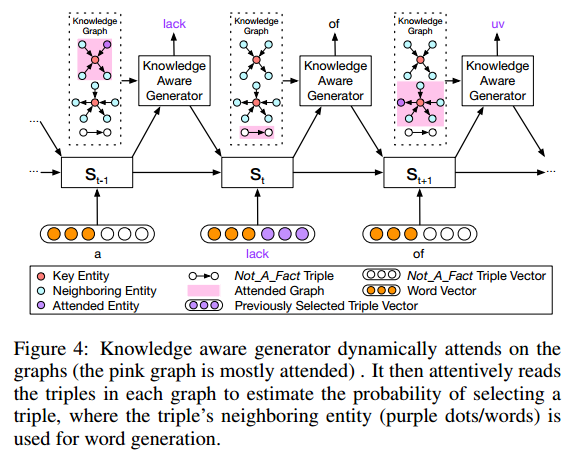
在生成时,不同于静态图注意力机制,模型会读取所有相关的子图,而不是当前词对应的子图,并计算decoder state $s_t$ 时使用每一个子图 $g_i$ 的概率:
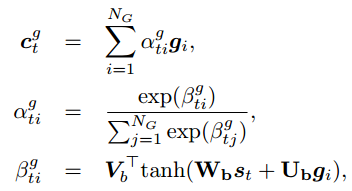
之后模型会计算选择decoder state $s_t$ 时每个子图 $g_i$ 中选择一个三元组 $k_j$ 来生成单词的概率:
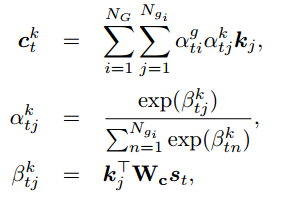
生成时,会根据计算结果,来选择是生成通用字(generic word)还是子图中的实体:
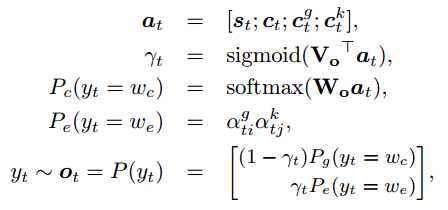
4. 损失函数
损失函数为预期输出与实际输出的交叉熵,除此之外,为了监控选择通用词还是实体的概率,又增加了一个交叉熵:
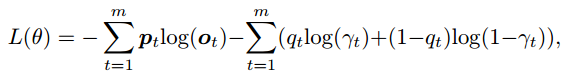
Experiment
实验相关细节
常识性知识图谱选用了ConceptNet,对话数据集选用了reddit的10M single-round 对话数据集,如果一个post-response不能以一个三元组表示(一个实体出现于post,另一个出现于response),就将这个数据去除(filter the original corpus with the knowledge triplets)。
然后对剩下的对话数据分为四类,一类是高频词,即每一条post的每一个词,都是最高频的25%的词;一类是中频词即25%-75%;一类是低频词即高于75%;最后一类是OOV词,每一条post包含有OOV词。
基线系统选择了如下三个:只从对话数据中生成response的seq2seq模型、存储了以TranE形式表示知识图谱的MemNet模型[Ghazvininejad et al., 2017]、从三元组中copy一个词或生成通用词的CopyNet模型[Zhu et al., 2017]。
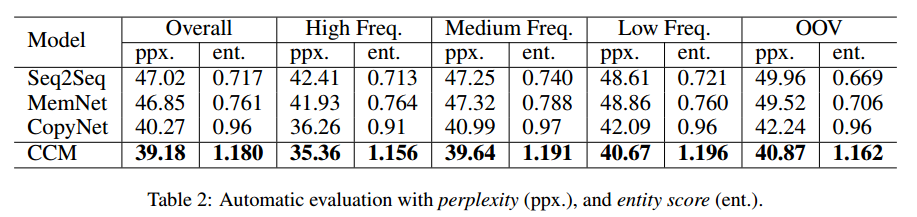
而选用metric的时候,采用了刻画回复内容是否语法正确且贴近主题的perplexity,以及有多少知识图谱实体被生成的entity score。
实验结果
如下图所示为根据perplexity和entity score进行的性能比较,可见CCM的perplexity最低,且选取entity的数量最多。并且,在低频词时,选用的entity更多,这表示在训练时比较罕见的词(实体)会需要更多的背景知识来生成答复。
另外,作者还采用crowdsourcing的方式来人为审核response的质量,并采用了两种度量值:appropriateness(内容是否语法正确,是否与主题相关,是否有逻辑)和 informativeness(内容是否提供了post之外的新信息)。

从上图可见,CCM对于三个基线系统来说,都有将近60%的回复是更优的。并且在OOV数据集上,CCM比seq2seq不知道高到哪里去了,这是由于CCM对于这些低频词或未登录词,可以用知识图谱去补全,而seq2seq没有这样的知识来源。
如下图所示,当在post中遇到未登录词”breakable”时,seq2seq和MemNet都只能输出一些通用的、模棱两可的、毫无信息量的回复。CopyNet能够利用知识图谱输出一些东西,但是并不合适。而CCM却可以输出一个合理的回复。

Knowledge Diffusion for Neural Dialogue Generation
http://aclweb.org/anthology/P18-1138
Motivation
和前面论文的描述类似,对话系统需要加入common knowledge,就不再赘述。论文的不同之处在于,作者认为对话系统应该具备通过当前会话中包含的facts发散到基于知识图谱的相似实体上:
- facts matching: 尽管有些对话是与facts相关的询问(inquiries),即主体和关系可以很容易被识别出来,但是对于某些对话,主体和关系是难以捉摸的,给准确的facts matching造成麻烦。下图展示了一个示例:Item 1 和 2 都在谈论电影”Titanic”,其中item 1是个典型的问答式对话,而item 2则是一个知识相关的没有任何显式关系的聊天式对话(chit-chat)。在item 2中去定义准确的fact match是非常困难的。

- entity diffusion:另一个显著的现象是,对话常常会从一个实体转移到另一个实体。如item 3 和 4 都和实体”Titanic”有关,然而回复中的实体都是其他的类似的电影。像这样的发散式关系,能够在现有的知识图谱三元组中去捕捉到它们的情况是十分罕见的。
因此,论文提出了一个神经知识发散(Neural Knowledge Diffusion, NKD)对话系统。NKD先去匹配对话与相关的事实(facts),之后匹配到的事实会用来发散到相似的实体,最后通过获取到的所有知识项来生成回复。
Model
Overview
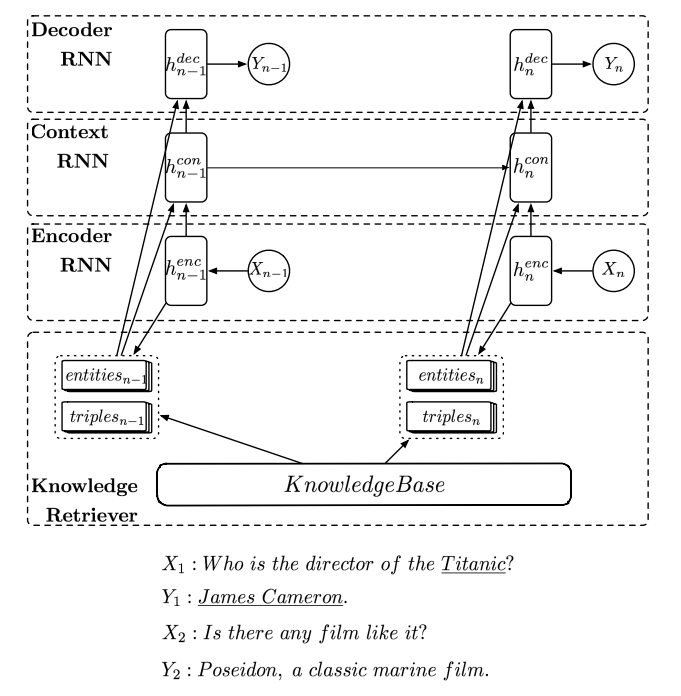
论文构建了一个多轮对话(Multi-turn)模型。模型由四部分组成:
- 一个将输入utterance $X$ 编码成向量的encoder。
- 一个用来记录整个会话中对话状态的上下文RNN。它将utterance的向量作为输入,并在每一轮对话中输出一个用来指引生成回复的向量。
- 一个用来生成response $Y$ 的decoder。
- 一个用来在每轮对话执行事实匹配(facts matching)和实体发散(diffuses to similar entities)的知识搜索器(knowledge retriever)。
1. Encoder
为了捕捉不同层面的信息,作者通过两个独立的RNN来学习utterance的表示,得到两个隐藏状态序列:
$H^C=(h_1^C, h_2^C, …, h_{Nx}^C)$ 和 $H^K=(h_1^K, h_2^K, …, h_{Nx}^K)$ 。
$h_{Nx}^C$ 作为之后用来追踪对话状态的上下文RNN的输入;$h_{Nx}^K$ 应用在knowledge retriever中,用来将知识实体关系编码进输入的utterance。上图 $X_1$ 中”director”和”Titanic”就是knowledge elements。
2. Knowledge Retriver
Knowledge retriever从知识库中抽取固定数量的facts并指出它们的重要程度。
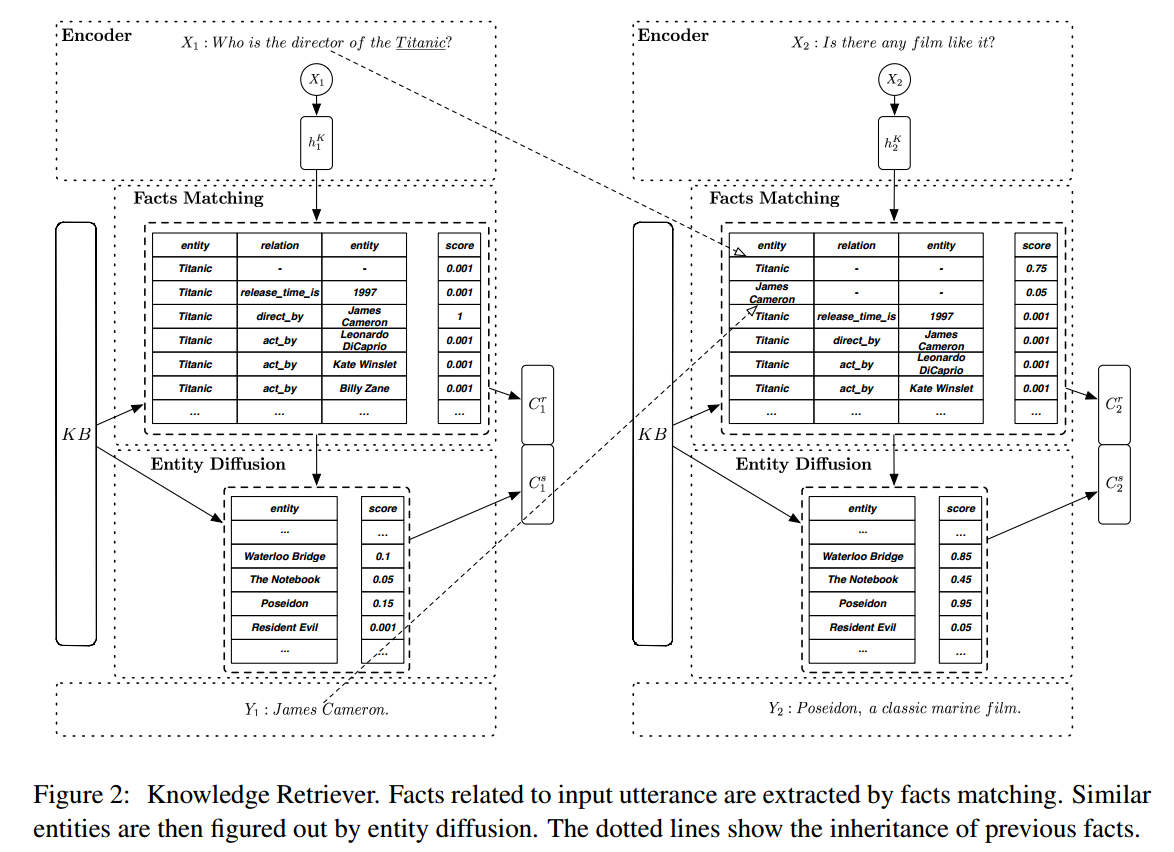
- Facts Matching
给定一个input utterance $X$,通过字符串匹配(string matching)、实体链接(entity linking)或命名实体识别(named entity recognition)来从知识库和对话历史中抽取$N_f$个相关facts $F = \{f_1,f_2,…,f_{N_f}\}$。$F$ 中的每个triplet的embedding通过简单地将entities和relation的embedding取均值得到 $h_f = \{h_{f_1},h_{f_2},…,h_{f_{N_f}}\}$。
之后计算每个fact和input utterance之间的相关系数(范围从0到1):
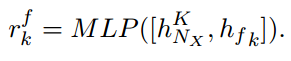
对于多轮对话,出现在之前的utterance的实体也会继承并保存在 $F$ 中。作者通过加权平均来计算相关事实表示(relevant fact representation) $C^f$:
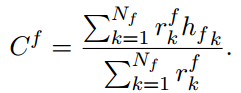
- Entity Diffusion
作者计算了知识库中的所有实体(除了已经在之前的utterance出现过的实体)与相关fact的相似系数 $r^e$(范围从0到1):
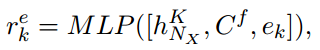
这里$e^k$是entity embedding。得分最高的$N_e$个实体被视作相似实体。相似实体表示(similar entity representation)$C^s$:
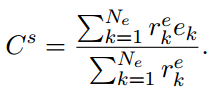
3. Context RNN
Context RNN 记录了utterance (sentence) level对话状态。Context RNN考虑了utterance表示和知识表示。
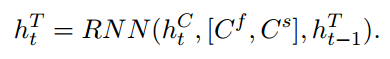
4. Decoder
- Vanilla decoder 仅通过 $C$, $R$ 产生response $Y$:
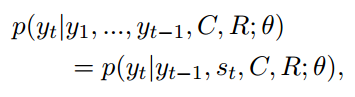
- Probabilistic gated decoder 使用了一个门控变量 $z_t$ 来表明位于第t个位置的词应该从普通词中产生还是从知识实体中产生:
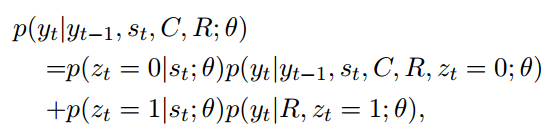
其中 $p(z_t|s_t;\theta)$ 通过逻辑回归来计算;$p(y_t|R,z_t=1;\theta)$ 近似于知识项(knowledge items)的相关系数。
考虑到在生成回复中,如果一个实体被反复使用,生成的回复的多样性将会减小。因此,当一个知识项出现在回复中时,其相应的相关系数应该减小,以避免一个item出现多次。为此,作者提出了两种范围追踪机制(coverage tracking mechanisms):1) Mask coefficient tracker 直接将出现的item的系数减少到0来保证其不会在回复中再次出现;2) Coeffient attenuation tracker :
Experiment
Detail
encoder使用512d Bi-LSTM;context RNN使用1024d LSTM;普通词汇、实体词、关系词共享同一个512d word embedding;使用Adam算法进行参数优化,梯度截断设为5.0。
对比实验使用了3个baseline模型:
Seq2Seq:最基本的RNN encoder-decoder模型。
HERD:一个分级RNN encoder-decoder模型。
GenDS:一个生成式神经网络对话系统,具有从输入文本和相关知识库生成回复的功能[Zhu et al., 2017]。
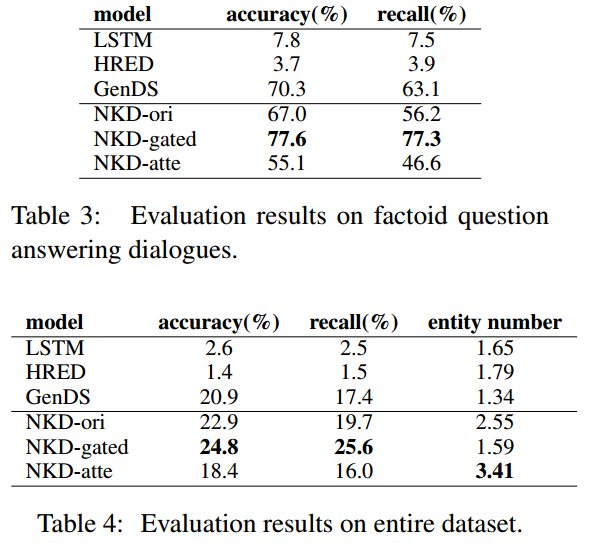
尝试了3种NKD的变种模型:
NKD-ori:使用基础的decoder和一个mask coefficient tracker。
NKD-gated:加入了probabilistic gated decoder和一个mask coefficient tracker。
NKD-atte:使用基础的decoder和一个coefficient attenuation tracker。
Result
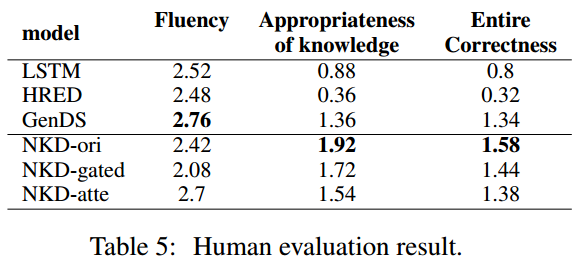
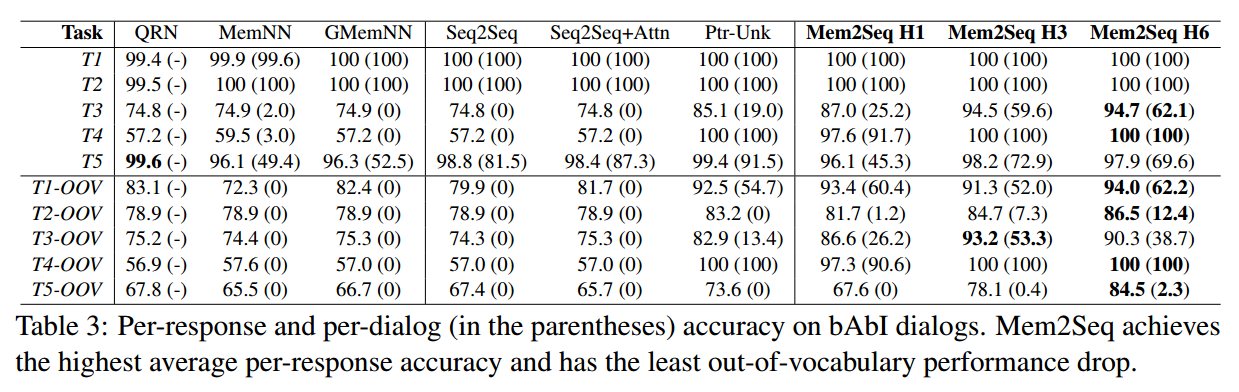
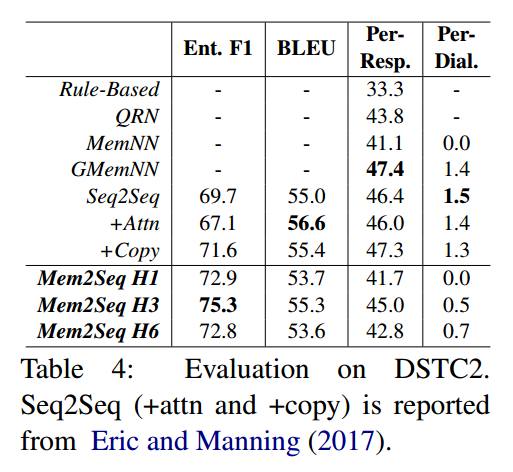
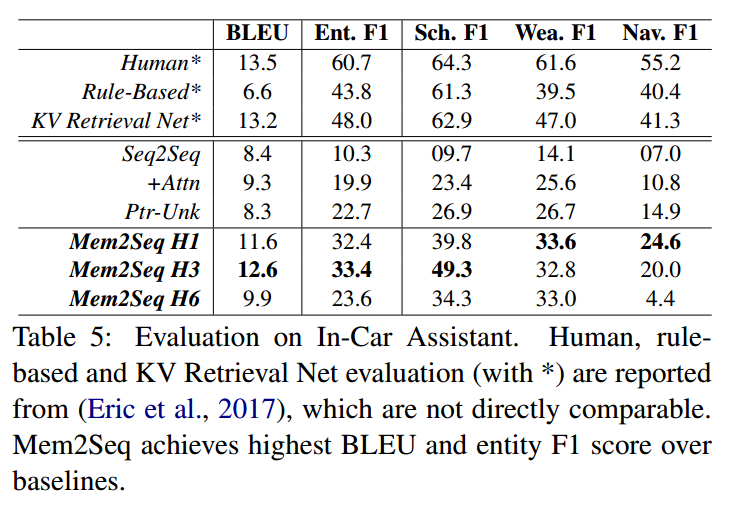
Mem2Seq: Effective Incorporating Knowledge Based into End-to-End Task-Orient Dialog Systems
https://arxiv.org/pdf/1804.08217.pdf
Motivation
近来,很多端到端对话系统都引入了基于注意力机制的copy-mechanism,将单词直接从输入文本copy到输出回复。使用这样的机制,使得即便是对话历史中出现了unknown的token,模型也能产生正确相关的实体词。
然而,尽管copy-mechanism被证明是很成功的,但它同样面临这两个主要问题:1)出于对RNN不适合处理超长文本的限制的考虑,将外部KB信息引入RNN隐藏状态的有效性有待商榷。 2)处理长文本序列的时间开销巨大,尤其是引入注意力机制之后。
另一方面,end-to-end memory networks[Sukhbaatar et al., 2015]是一个在巨大外部记忆进行循环attention操作的模型。它将外部记忆编入几个embedding矩阵,利用query向量反复读取记忆。这种方法可以记忆外部KB信息,并且快速地编码长对话历史。另外这种multi-hop的机制从实验结果来看,其对于推理任务是极其重要的。但是,MemNN只能从预定义的候选池中选择回复而不是逐个生成单词;而且对记忆的query需要显式设计而不是通过模型自行学得,也缺少时下流行的copy机制。
为了解决这些问题,论文提出了一个新的框架Mem2Seq,来通过端到端的方法学习生成面向特定任务的对话。总的来说,论文中的模型将现有的MemNN框架扩展为一个文本生成式架构,使用全局multi-hop注意力从历史对话和KB中直接copy单词生成回复。
Model
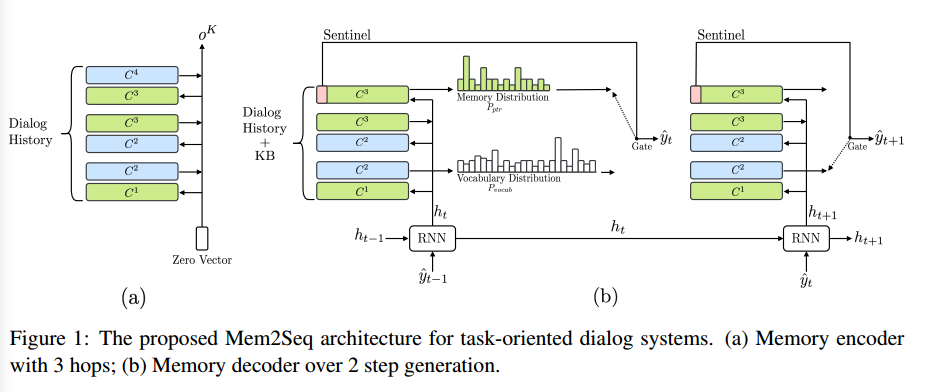
模型由两部分组成:MemNN encoder生成对话历史的向量表示;memory decoder从记忆中读取和copy来生成回复。
对话历史定义为一个tokens序列:$X = \{ x_1, \dots, x_n, sentinel \}$ , $sentinel$ 是一个标志字符;
KB元组定义为 $B=\{ b_1, \dots, b_l \}$;$U=[B;X]$;
$Y=\{ y_1, \dots, y_m \}$ 为预期输出序列;
另设一个和预期输出对其的预期指针序列:$PTR=\{ ptr_1, \dots, ptr_m \}$
Memory Encoder
encoder只用来加载和编码dialogue history $X$。
MemNN中的memories是一系列可训练的embedding矩阵 $C = \{ C^1, \dots , C^{K+1} \}$,每个矩阵将tokens映射为vectors。
$q^k$ 为query vector; $q^1$ 固定为零向量。
模型将会循环K个hop:
原版MemNN对memory有两个embedding matrices:input embedding matrix $A$ 和output embedding matrix $C$,分别表示存入memory时输入单词的embedding和读取memory时隐语义的embedding。Mem2Seq中实际上也有上述两个embedding matrices,并采用了MemNN中的adjacent weight tying策略,即 $A^{k+1}=C^k$。
Encoder最后输出 $o^K$ 作为decoder的输入。(作者提供的源代码是将 $q^{K+1}$ 作为decoder输入)。
Memory Decoder
Decoder包含一个GRU和一个MemNN,MemNN加载dialogue history和KB的拼接 $U$。Decoder的MemNN和encoder的MemNN不共享参数。
Encoder的输出 $o^K$ 作为GRU的初始隐藏状态 $h_0$。
t时刻,GRU的隐藏状态 $h_t$ 作为decoder MemNN的query vector,经过MemNN的K个hop,得到decoder memory output $o^K$。之后decoder会生成vocab和pointer两种分布:
$o^1$ 为decoder MemNN的hop 1的memory output,$p^K$ 为decoder MemNN的hop K的attention score。
Memory Content
Memory整合了word-level的dialogue history和KB tuples。每个KB tuple的representation是subject, relation, object的embedding之和。如果pointer指向KB tuple,则输出为tuple的object。
Experiment
Detail
使用Adam optimizer,学习率在1e-3到1e-4之间。MemNN采用了hops K = 1, 3, 6三种来对比实验。Dropout rate在0.1到0.4之间,同时还将部分输入word mask成unknown token来模拟OOV情况。
Result